
Flash Attention作者最新播客:英伟达GPU统治三年内将终结
Flash Attention作者最新播客:英伟达GPU统治三年内将终结英伟达还能“猖狂”多久?——不出三年! 实现AGI需要新的架构吗?——不用,Transformer足矣! “近几年推理成本下降了100倍,未来还有望再降低10倍!” 这些“暴论”,出自Flash Attention的作者——Tri Dao。
来自主题: AI资讯
9459 点击 2025-09-29 22:06
 搜索
搜索
英伟达还能“猖狂”多久?——不出三年! 实现AGI需要新的架构吗?——不用,Transformer足矣! “近几年推理成本下降了100倍,未来还有望再降低10倍!” 这些“暴论”,出自Flash Attention的作者——Tri Dao。
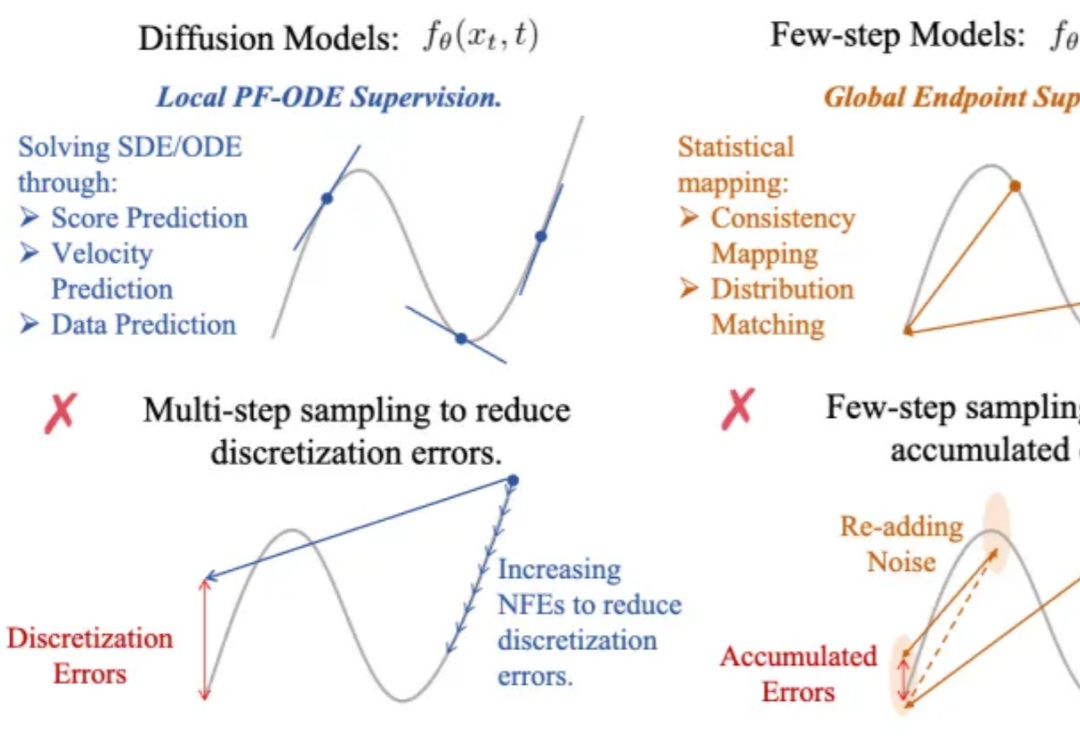
生成式AI的快与好,终于能兼得了?
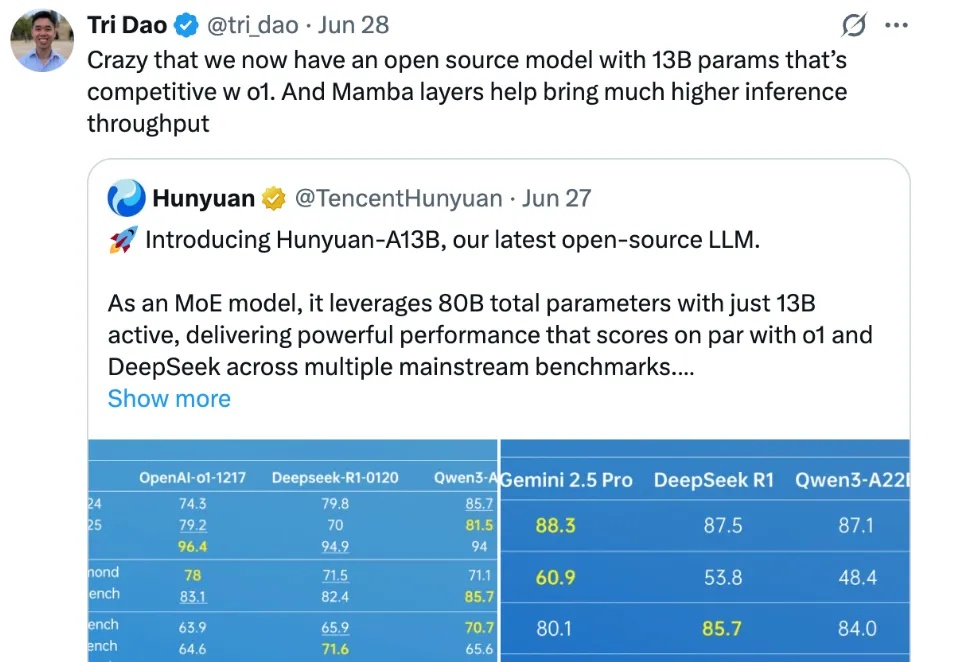
腾讯混元,在开源社区打出名气了。
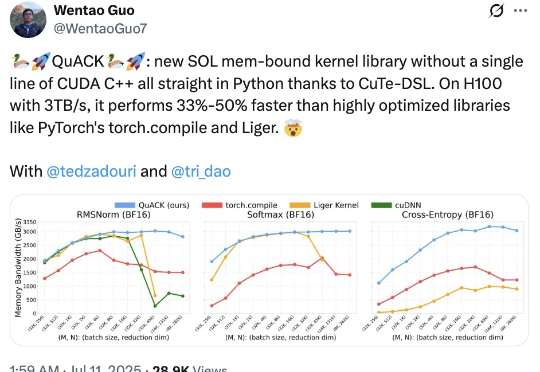
无需CUDA代码,给H100加速33%-50%! Flash Attention、Mamba作者之一Tri Dao的新作火了。
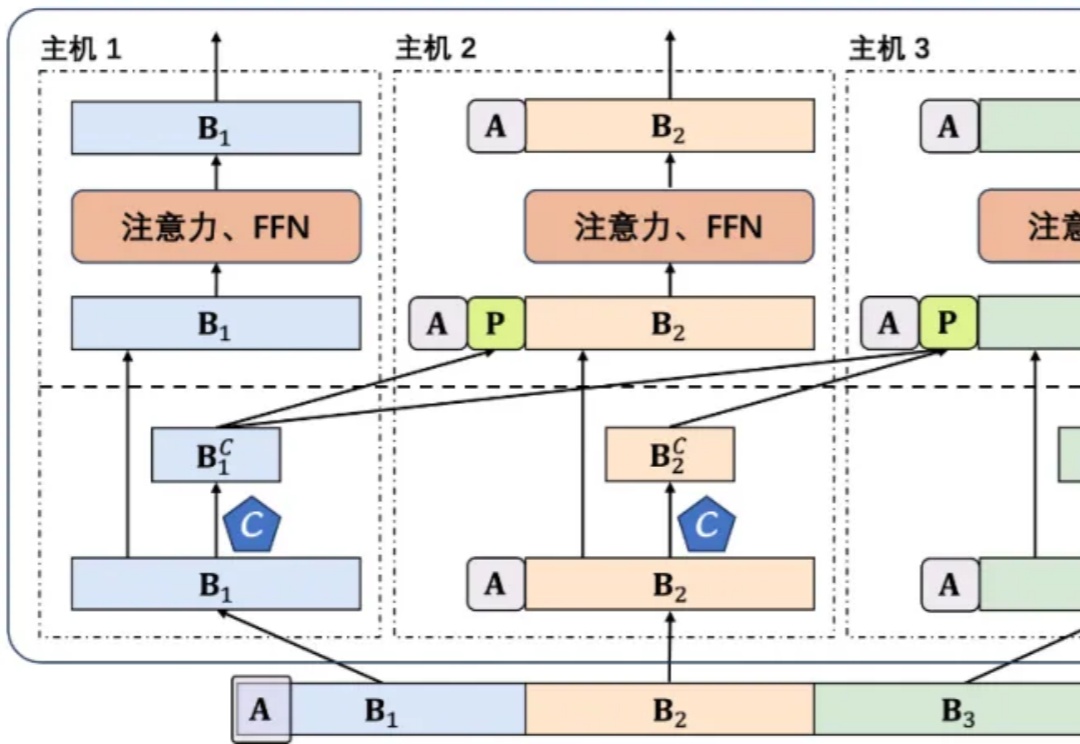
在 ChatGPT 爆火两年多的时间里,大语言模型的上下文窗口长度基准线被拉升,以此为基础所构建的长 CoT 推理、多 Agent 协作等类型的高级应用也逐渐增多。
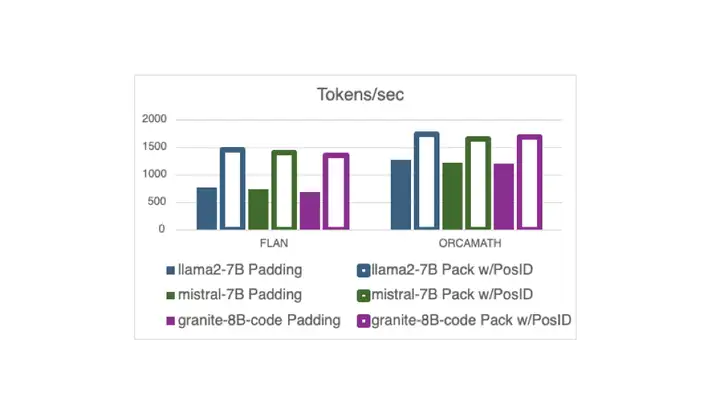
现在,在 Hugging Face 中,使用打包的指令调整示例 (无需填充) 进行训练已与 Flash Attention 2 兼容,这要归功于一个 最近的 PR 以及新的 DataCollatorWithFlattening。 它可以在保持收敛质量的同时,将训练吞吐量提高多达 2 倍。继续阅读以了解详细信息!

众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。
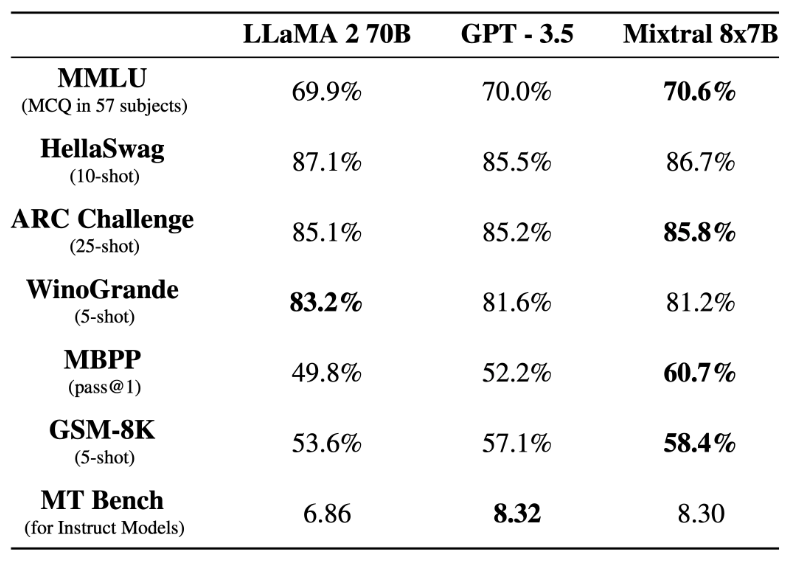
前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。